
Get Started ^0.8.0
LLooM is currently designed as a Python package for computational notebooks. Follow the instructions on this page to get started with LLooM Workbench on your dataset. We suggest starting with this template Colab Notebook.
1: Installation
First, install the LLooM Python package, available on PyPI as text_lloom. We recommend setting up a virtual environment with venv or conda.
pip install text_lloomNow, you can use the LLooM package in a computational notebook! Create your notebook (i.e., with JupyterLab) and then you can import the LLooM package:
import text_lloom.workbench as wb2a: Quick LLooM instance (OpenAI defaults)
By default, LLooM uses the OpenAI API under the hood to support its core operators (using GPT-4o mini and GPT-4o). If you use this default setting, you first need to locally set the OPENAI_API_KEY environment variable to use your own account.
import os
os.environ["OPENAI_API_KEY"] = "sk-YOUR-KEY-HERE"TIP
LLooM provides (1) cost estimation functions that automatically run before operations that make calls to the OpenAI API and (2) cost summary functions to review tracked usage, but we encourage you to monitor usage on your account as always.
After loading your data as a Pandas DataFrame, create a new LLooM instance. You will need to specify the name of the column that contains your input text documents (text_col). The ID column (id_col) is optional.
l = wb.lloom(
df=df,
text_col="your_doc_text_col",
id_col="your_doc_id_col", # Optional
# By default, when not specified, uses the following models:
# - distill_model: gpt-4o-mini
# - cluster_model: text-embedding-3-large
# - synth_model: gpt-4o
# - score_model: gpt-4o-mini
)2b: Custom LLooM instance
Alternatively, users can specify other LLMs to support the LLooM operators, including:
- Different OpenAI models (e.g., swapping in
gpt-4for the Synthesis operator) - Alternative LLM providers (e.g., Gemini, Claude)
- Open source models (e.g., Llama, Mistral)
Please visit the Custom Models page for information about these custom setups along with sample notebooks. The custom LLM setup also allows users to specify custom rate limits for each operator.
3: Concept generation
Next, you can go ahead and start the concept induction process by generating concepts. The seed term can steer concept induction towards more specific areas of interest (e.g., social issues" for political discussion or "evaluation methods" for academic papers). You can omit the seed parameter if you do not want to use a seed.
await l.gen(
seed="your_optional_seed_term", # Optional
)We also provide a one-function "auto" mode that grants less control over the process, but simplifies the concept generation and scoring process into a single function. If you use the gen_auto function, you do not need to run concept scoring, but can directly proceed to visualize the results.
score_df = await l.gen_auto(
max_concepts=5,
seed="your_optional_seed_term", # Optional
)4: Concept scoring
Review concepts
Review the generated concepts and select concepts to inspect further:
l.select()In the output, each box contains the concept name, concept inclusion criteria, and representative example(s). 
→ Exporting concepts
If you'd like to export the generated concepts, you can access them directly from the LLooM instance from l.concepts and the to_dict() helper:
concepts = l.concepts
for concept_id, concept in concepts.items():
concept_dict = concept.to_dict()
print(concept_dict) # Sample output: {'id': 'ace2184a-20eb-4cbc-a4a0-5082d7f4532b', 'name': 'Political and Government Accountability', 'prompt': 'Does the text address issues related to holding political figures or government entities accountable?', 'example_ids': ['2476', '1876', '8926', '3076'], 'active': False, 'summary': None, 'seed': None}Score concepts
Then, apply these selected concepts to the full dataset with score(). This function will score all documents with respect to each concept to indicate the extent to which the document matches the concept inclusion criteria.
score_df = await l.score()→ Score additional data
Now that you induced concepts from the original dataset in your LLooM instance, you can also apply these concepts to score new data by providing a dataframe to the score() function. The provided dataframe must contain column names matching the original df (i.e., the same text_col and id_col).
df_2 = # Load new dataframe with column names matching df
score_df_2 = await l.score(df=df_2)→ Score all concepts
If you would like to score all generated concepts rather than selecting concepts from the l.select() widget, you can set the score_all parameter.
score_df = await l.score(score_all=True)5: Visualization
Now, you can visualize the results in the main LLooM Workbench view. An interactive widget will appear when you run this function:
l.vis()Check out Using the LLooM Workbench for a more detailed guide on the visualization components. 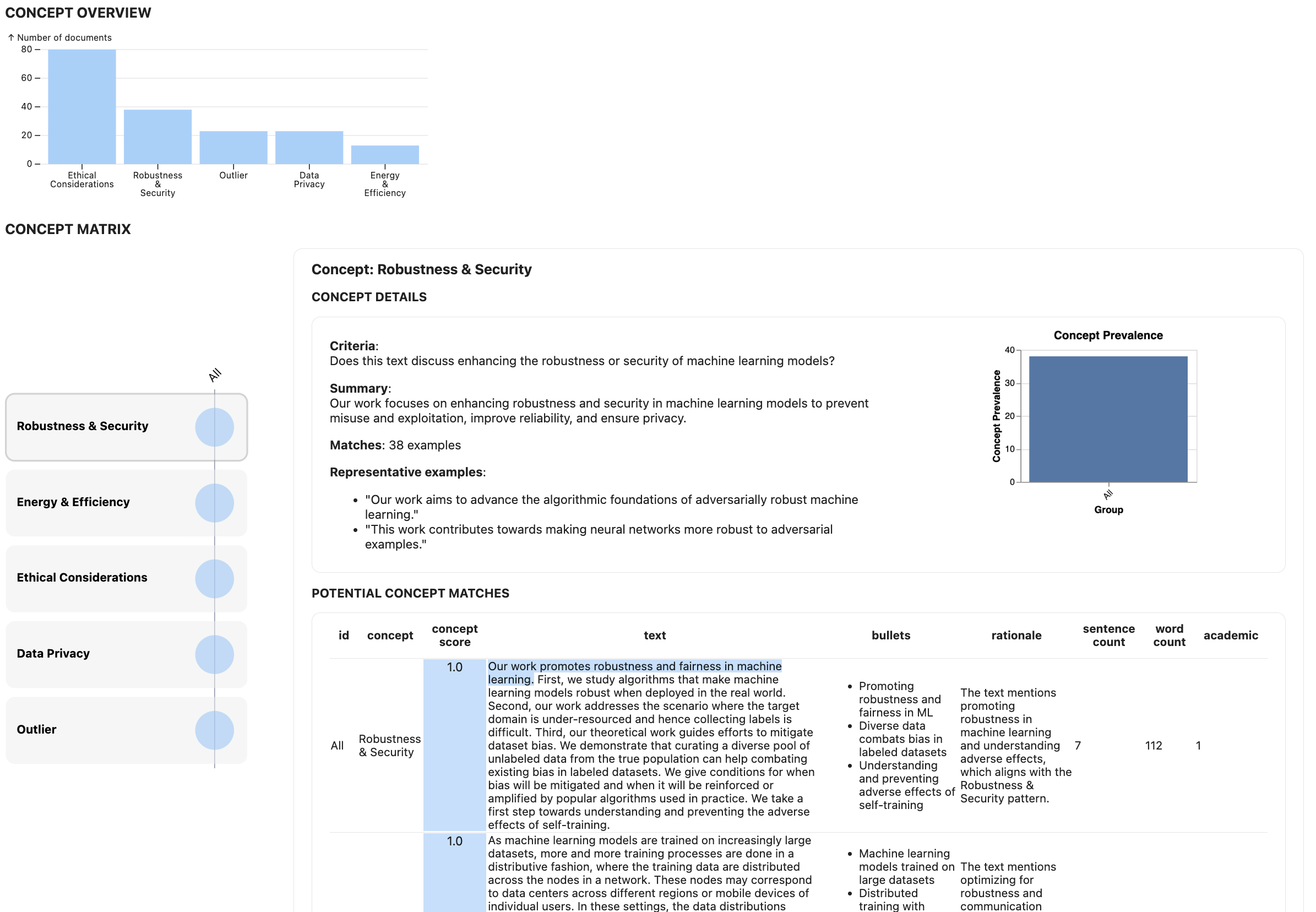
Add slices (columns)
If you want to additionally slice your data according to a pre-existing metadata column in your dataframe, you can optionally provide a slice_col. Numeric or string columns are supported. Currently, numeric columns are automatically binned into quantiles, and string columns are treated as categorical variables.
l.vis(slice_col="n_likes")Optional parameters for slices:
max_slice_bins: For numeric columns, the maximum number of bins to create (default=5)slice_bounds: For numeric columns, the manual bin boundaries to use (ex: [0, 10, 50, 100])
Normalize counts
By default, the concept matrix shows the raw document counts. You can normalize by concept, meaning that the size of the circles in each concept row represents the fraction of examples in that concept that fall into each slice column.
l.vis(slice_col="n_likes", norm_by="concept")You can also normalize by slice so that the size of circles in each slice column represents the fraction of examples in that slice that fall into each concept row.
l.vis(slice_col="n_likes", norm_by="slice")
Manual concepts
You may also manually add your own custom concepts by providing a name and prompt. This will automatically score the data by that concept.
await l.add(
# Your new concept name
name="Government Critique",
# Your new concept prompt
prompt="Does this text criticize government actions or policies?",
)Then, re-run the vis() function to see the new concept results.
Saving and exporting
Submit your results
🖼️ ✨ Submit your work for a chance to be featured!
If you'd like to share what you've done with LLooM or would like your work featured in a gallery of results, please submit your LLooM instance with the submit() function! If your submission is selected, we'll reach out to you to follow up and hear more about your work with LLooM.
To submit your results, you just need to run the following function:
l.submit()You will be prompted to provide a few more details:
- Email address: Please provide an email address so that we can contact you if your work is selected.
- Analysis goal: Share as much detail as you'd like about your analysis: What data were you using? What questions were you trying to answer? What did you find?
Save LLooM instance
You can save your LLooM instance to a pickle file to reload at a later point.
l.save(folder="your/path/here", file_name="your_file_name")You can then reload the LLooM instance by opening the pickle file:
import pickle
with open("your/path/here/your_file_name.pkl", "rb") as f:
l = pickle.load(f)Export results
Export a summary of the results in Pandas Dataframe form.
export_df = l.export_df()The dataframe will include the following columns:
concept: The concept namecriteria: The concept inclusion criteriasummary: A generated summary of the examples that matched this conceptrep_examples: A few representative examples for the concept from the concept generation phaseprevalence: The proportion of documents in the dataset that matched this conceptn_matches: The number of documents in the dataset that matched this concepthighlights: An illustrative sample of n=3 highlighted quotes from documents that matched the concept that were relevant to the concept
Cost tracking
LLooM provides cost estimation functions as well as cost summary functions to review usage.
estimate_gen_cost
l.estimate_gen_cost(params=None, verbose=False)
Estimates the cost of running gen() with the given parameters. If no parameters are provided, the function uses auto-suggested parameters. The function is automatically run within calls to gen() for the user to review before proceeding with concept generation.
estimate_score_cost
l.estimate_score_cost(n_concepts=None, verbose=False)
Estimates the cost of running score() on the provided number of concepts. If n_concepts is not specified, the function uses the current number of active (selected) concepts. The function is automatically run within calls to score() for the user to review before proceeding with concept scoring.
summary
l.summary(verbose=True)
Displays a cumulative summary of the (1) Total time, (2) Total cost, and (3) Tokens for the entire LLooM instance.
- Total time: Displays the total time required for each operator. Each tuple contains the operator name and the timestamp at which the operation completed.
- Total cost: Displays the calculated cost incurred by each operator (in US Dollars).
- Tokens: Displays the overall number of tokens used (total, in, and out)
Sample output:
Total time: 25.31 sec (0.42 min)
('distill_filter', '2024-03-08-02-45-20'): 3.13 sec
('distill_summarize', '2024-03-08-02-45-21'): 1.80 sec
('cluster', '2024-03-08-02-45-25'): 4.00 sec
('synthesize', '2024-03-08-02-45-42'): 16.38 sec
Total cost: $0.14
('distill_filter', '2024-03-08-02-45-20'): $0.02
('distill_summarize', '2024-03-08-02-45-21'): $0.02
('synthesize', '2024-03-08-02-45-42'): $0.10
Tokens: total=67045, in=55565, out=11480Rate limits
Depending on the volume of data you are analyzing and the details of your OpenAI account/organization, you may run into OpenAI API rate limits (with respect to tokens per minute (TPM) or requests per minute (RPM)). LLooM provides several avenues to address rate limits.
Modifying underlying models
By default, LLooM currently uses gpt-4o-mini for the Distill and Score operators, gpt-4o for the Synthesize operator, and text-embedding-3-large for the Cluster operator. These values are set in workbench.py. However, users can specify different models for each of these operators within the LLooM instance. See the Custom Models page for examples with other OpenAI models, other LLM APIs, and open source models.
Customizing wait times
LLooM has built-in functionality for batching asynchronous requests to avoid rate limit issues. However, the necessary batch size and timing may vary across different users depending on details of their dataset and account.
With the Custom Models option, users can override the number of requests in a batch and the length of time to wait between batches with the rate_limit parameter.
The current defaults are defined using the rate_limit field in MODEL_INFO in llm_openai.py. For OpenAI models, it may be helpful to refer to your organization's own rate limits to set these values.
Batching score operations
The Score operator in particular may run into rate limits because it initiates a higher volume of concurrent requests to score all documents for all selected concepts. By default, scoring is applied individually for each concept and each document (batch_size=1) to produce more reliable scores.
However, users can opt to increase the batch size, which will score multiple documents at a time for a given concept. This will reduce the number of unique API calls, but may sacrifice scoring reliability.
score_df = await l.score(
batch_size=5,
)Skipping confirmation input
To avoid making unintended LLM calls, the workbench functions require user confirmation to proceed with concept generation and scoring ("Proceed with generation? (y/n)" and "Proceed with scoring? (y/n)"). However, users can bypass this confirmation message by setting debug=False, which will also avoid printing debug information.
# Sample function calls bypassing confirmation message
await l.gen(debug=False)
score_df = await l.score(debug=False)
score_df = await l.gen_auto(max_concepts=5, debug=False)
await l.add(name="", prompt="", debug=False)LLooM Operators
If you'd like to dive deeper and reconfigure the core operators used within LLooM (like the Distill, Cluster, and Synthesize operators), you can access the base functions from the concept_induction module:
import text_lloom.concept_induction as ciPlease refer to the API Reference for details on each of the core LLooM operators.