
What is LLooM?
LLooM is a data analysis tool for unstructured text data, such as social media posts, paper abstracts, and articles. Manual text analysis is laborious and challenging to scale to large datasets, and automated approaches like topic modeling and clustering tend to focus on lower-level keywords that can be difficult for analysts to interpret.
By contrast, the LLooM algorithm turns unstructured text into meaningful high-level concepts that are defined by explicit inclusion criteria in natural language. For example, on a dataset of toxic online comments, while a BERTopic model outputs "women, power, female", LLooM produces concepts such as "Criticism of gender roles" and "Dismissal of women's concerns". We call this process concept induction: a computational process that produces high-level concepts from unstructured text.
The LLooM Workbench is an interactive text analysis tool that visualizes data in terms of the concepts that LLooM surfaces. With the LLooM Workbench, data analysts can inspect the automatically-generated concepts and author their own custom concepts to explore the data.
🚧 LLooM is a research prototype
LLooM originated from a research project (more info here). The system is still under active development. We would appreciate your feedback as we expand beyond our prototype to support a broader range of datasets and analysis goals! Check out our Github repo if you'd like to contribute.
The LLooM Python package consists of two components:
LLooM Workbench—a higher-level API for computational notebooks that surfaces interactive notebook widgets to inspect data by induced concepts.LLooM Operators—a lower-level API for the operators that underlie the LLooM algorithm.
→ Check out the Get Started page to try out the LLooM Workbench!
What can I do with LLooM?
LLooM can assist with a range of data analysis goals—from preliminary exploratory analysis to theory-driven confirmatory analysis. Analysts can review LLooM concepts to interpret emergent trends in the data, but they can also author concepts to actively seek out certain phenomena in the data. Concepts can be compared with existing metadata or other concepts to perform statistical analyses, generate plots, or train a model.

Check out the Examples section to walk through case studies using LLooM, including:
- 🇺🇸📱 Political social media: Case Study | Colab NB
- 💬⚖️ Content moderation: Case Study | Colab NB
- 📄📈 HCI paper abstracts: Case Study | Colab NB
- 📝🤖 AI ethics statements: Case Study | Colab NB
Workbench features
The LLooM Workbench is an interactive text analysis tool for computational notebooks like Jupyter and Colab. After running concept induction, the Workbench can display an interactive visualization like the one below. 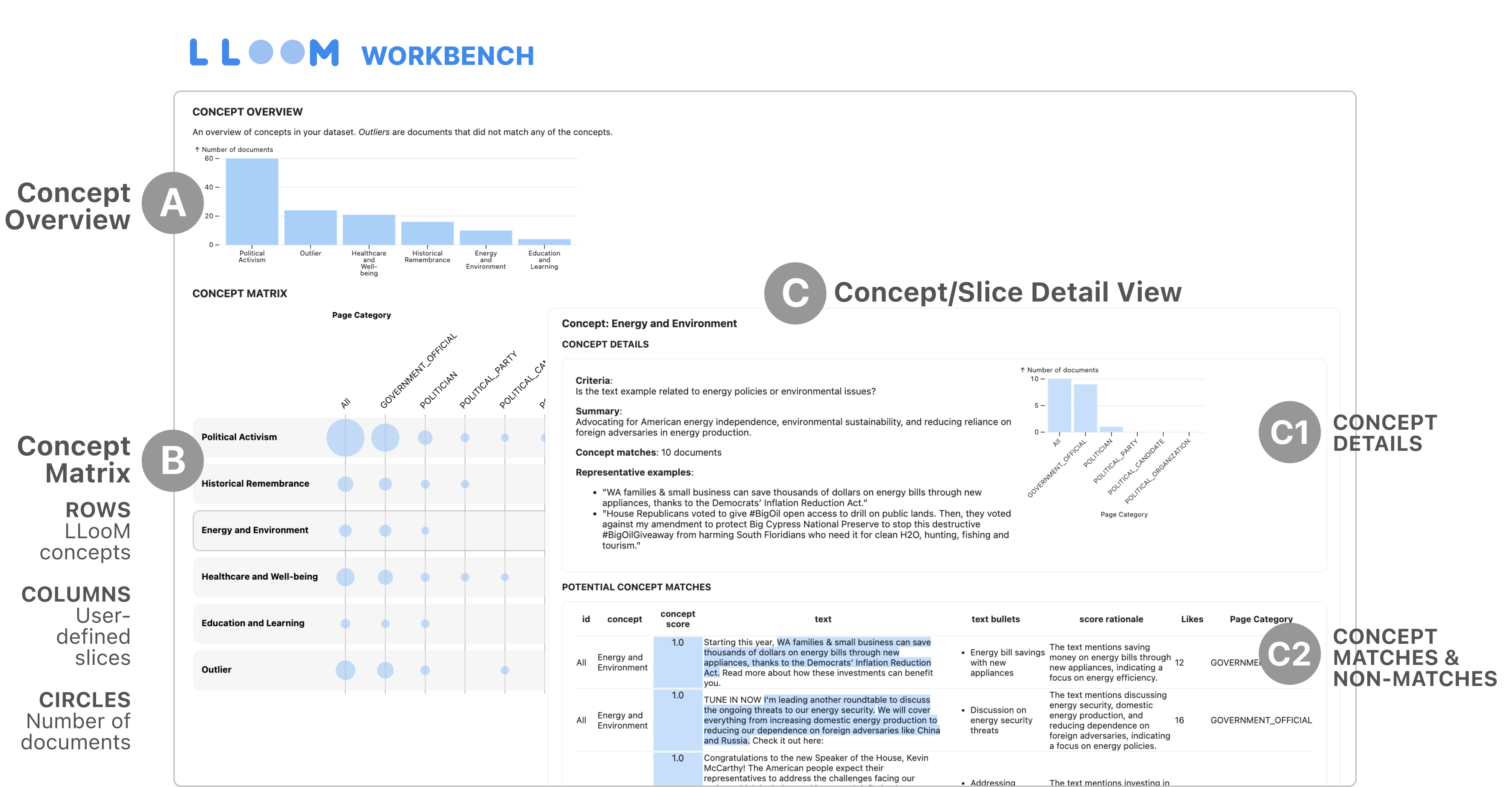
LLooM Workbench features include:
- A: Concept Overview: Displays an overview of the dataset in terms of concepts and their prevalence.
- B: Concept Matrix: Provides an interactive summary of the concepts. Users can click on concept rows to inspect concept details and associated examples. Aids comparison between concepts and other metadata columns with user-defined slice columns.
- C: Detail View (for Concept or Slice):
- C1: Concept Details: Includes concept information like the Name, Inclusion criteria, Number of doc matches, and Representative examples.
- C2: Concept Matches and Non-Matches: Shows all input documents in table form. Includes the original text, bullet summaries, concept scores, highlighted text that exemplifies the concept, score rationale, and metadata columns.
→ See the Using the LLooM Workbench page for more detail on the Workbench.
How does LLooM work?
LLooM is a concept induction algorithm that extracts and applies concepts to make sense of unstructured text datasets. LLooM leverages large language models (specifically GPT-4o and GPT-4o mini in the current implementation) to synthesize sampled text spans, generate concepts defined by explicit criteria, apply concepts back to data, and iteratively generalize to higher-level concepts.

Overview
LLooM samples extracted text and iteratively synthesizes proposed concepts of increasing generality. Once data has been synthesized into a concept, we can move up to the next abstraction level; we can generalize from smaller, lower-level concepts to broader, higher-level concepts by repeating the process with concepts as the input. Since concepts include explicit inclusion criteria, we can expand the reach of any generated concept to consistently classify new data through that same lens and discover gaps in our current concept set. These core capabilities of synthesis, classification, and abstraction are what allow LLooM to iteratively generate concepts, apply them back to data, and bubble up to higher-level concepts. The algorithm consists of several core operators.
Operators
First, for the concept generation step, LLooM implements the Synthesize operator that prompts the LLM to generalize from provided examples to generate concept descriptions and criteria in natural language. Directly prompting an LLM like GPT-4 to perform this kind of synthesis produces broad, generic concepts rather than nuanced and specific conceptual connections (e.g., that a set of posts are feminist-related, rather than that they all constitute men’s critiques of feminism). While generic concepts may be helpful for an overarching summary of data, analysts seek richer, more specific concepts that characterize nuanced patterns in the data. Additionally, such synthesis is not possible for text datasets that exceed LLM context windows.
To address these issues, the LLooM algorithm includes two operators that aid both data size and concept quality: (1) a Distill operator, which shards out and scales down data to the context window while preserving salient details, and (2) a Cluster operator, which recombines these shards into groupings that share enough meaningful overlap to induce meaningful rather than surface-level concepts from the LLM.

Then, for the concept scoring step, we leverage the zero-shot reasoning abilities of LLMs to implement a Score operator that labels data examples by applying concept criteria expressed as zero- shot prompts. With these labels, we can visualize the full dataset in terms of the generated concepts or further iterate on concepts by looping back to concept generation with the Loop operator.
What if the analyst wants to steer LLooM’s attention toward particular aspects of the data? LLooM allows the analyst to guide the system to attend to “social issues” for a political dataset, or “evaluation methods” for an academic papers dataset. The optional Seed operator accepts a user-provided seed term to condition the Distill or Synthesize operators, which can improve the quality and alignment of the output concepts. All of these operators work together to support analysts in performing concept induction and leading theory-driven data analyses.
About us
LLooM is a research prototype! You can read much more about the project, the method, and a variety of evaluations in our CHI 2024 publication: Concept Induction: Analyzing Unstructured Text with High-Level Concepts Using LLooM by Michelle S. Lam, Janice Teoh, James Landay, Jeffrey Heer, and Michael S. Bernstein.
If you find our tool helpful or use it in your work, we'd appreciate you citing our paper!
@article{lam2024conceptInduction,
author = {Lam, Michelle S. and Teoh, Janice and Landay, James and Heer, Jeffrey and Bernstein, Michael S.},
title = {Concept Induction: Analyzing Unstructured Text with High-Level Concepts Using LLooM},
year = {2024},
isbn = {9798400703300},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3613904.3642830},
doi = {10.1145/3613904.3642830},
booktitle = {Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems},
articleno = {933},
numpages = {28},
location = {Honolulu, HI, USA},
series = {CHI '24}
}Team members
This project was led by a team researchers in the Stanford Human-Computer Interaction Group in collaboration with the UW Interactive Data Lab.
Contact Us
Interested in the project or helping with future directions? We'd love to hear from you! Please feel free to contact Michelle Lam at mlam4@cs.stanford.edu, or check out our Github repository to contribute.
Acknowledgements
Thank you to the Stanford HCI Group and UW Interactive Data Lab for feedback on early versions of this work. This work was supported in part by IBM as a founding member of the Stanford Institute for Human-centered Artificial Intelligence (HAI) and by NSF award IIS-1901386. Michelle was supported by a Stanford Interdisciplinary Graduate Fellowship.